

Base64 编码浅析
Base64 常用于 Data URL 的内联中,这篇博客文章探讨两个问题:
- 为什么图片转成 Base64 编码,就可以直接内联到 HTML 中显示呢?
- 为什么 Base64 编码后,体积会增大 1/3 呢?
为什么 Base64 编码可以内联到 HTML 中?
我们知道 HTTP 协议是文本协议,不同于常规的二进制协议那样直接进行二进制传输。Base64 编码是从二进制到字符的过程,可用于在 HTTP 环境下传递较长的标识信息。
什么是 Base64 编码
首先 Base64 是一种编码算法,为什么叫做 Base64 呢?其实原因也很简单,是因为该算法共包含 64 个字符。包括大小写拉丁字母各 26 个、数字 10 个、加号 + 和斜杠 /,共 64 个字符。此外还有等号 = 用来作为后缀用途。
字符与索引的对应关系如下图所示。
| Value | Char | Value | Char | Value | Char | Value | Char |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 3 | C | 18 | S | 34 | i | 50 | y |
| 4 | D | 19 | T | 35 | j | 51 | z |
| 5 | E | 20 | U | 36 | k | 52 | 0 |
| 6 | F | 21 | V | 37 | l | 53 | 1 |
| 7 | G | 22 | W | 38 | m | 54 | 2 |
| 8 | H | 23 | X | 39 | n | 55 | 3 |
| 9 | I | 24 | Y | 40 | o | 56 | 4 |
| 10 | J | 25 | Z | 41 | p | 57 | 5 |
| 11 | K | 26 | a | 42 | q | 58 | 6 |
| 12 | L | 27 | b | 43 | r | 59 | 7 |
| 13 | M | 28 | c | 44 | s | 60 | 8 |
| 14 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
但,为什么 Base64 编码算法只支持 64 个字符呢?
首先,我们先回顾下 ASCII 码。ASCII 码的范围是 0-127,其中 0-31 和 127 是控制字符,共 33 个。其余 95 个,即 32-126 是可显示字符,包括数字、大小写字母、常用符号等。如下图所示(数据来自 维基百科):
| 二进制 | 十进制 | 十六进制 | 缩写 | Unicode 表示法 | 脱出字符 表示法 | 名称/意义 |
|---|---|---|---|---|---|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | ^@ | 空字符(Null) |
| 0000 0001 | 1 | 01 | SOH | ␁ | ^A | 标题开始 |
| 0000 0010 | 2 | 02 | STX | ␂ | ^B | 本文开始 |
| 0000 0011 | 3 | 03 | ETX | ␃ | ^C | 本文结束 |
| 0000 0100 | 4 | 04 | EOT | ␄ | ^D | 传输结束 |
| 0000 0101 | 5 | 05 | ENQ | ␅ | ^E | 请求 |
| 0000 0110 | 6 | 06 | ACK | ␆ | ^F | 确认回应 |
| 0000 0111 | 7 | 07 | BEL | ␇ | ^G | 响铃 |
| 0000 1000 | 8 | 08 | BS | ␈ | ^H | 退格 |
| 0000 1001 | 9 | 09 | HT | ␉ | ^I | 水平定位符号 |
| 0000 1010 | 10 | 0A | LF | ␊ | ^J | 换行键 |
| 0000 1011 | 11 | 0B | VT | ␋ | ^K | 垂直定位符号 |
| 0000 1100 | 12 | 0C | FF | ␌ | ^L | 换页键 |
| 0000 1101 | 13 | 0D | CR | ␍ | ^M | CR (字符) |
| 0000 1110 | 14 | 0E | SO | ␎ | ^N | 取消变换(Shift out) |
| 0000 1111 | 15 | 0F | SI | ␏ | ^O | 启用变换(Shift in) |
| 0001 0000 | 16 | 10 | DLE | ␐ | ^P | 跳出数据通讯 |
| 0001 0001 | 17 | 11 | DC1 | ␑ | ^Q | 设备控制一 (XON 激活软件速度控制) |
| 0001 0010 | 18 | 12 | DC2 | ␒ | ^R | 设备控制二 |
| 0001 0011 | 19 | 13 | DC3 | ␓ | ^S | 设备控制三 (XOFF 停用软件速度控制) |
| 0001 0100 | 20 | 14 | DC4 | ␔ | ^T | 设备控制四 |
| 0001 0101 | 21 | 15 | NAK | ␕ | ^U | 确认失败回应 |
| 0001 0110 | 22 | 16 | SYN | ␖ | ^V | 同步用暂停 |
| 0001 0111 | 23 | 17 | ETB | ␗ | ^W | 区块传输结束 |
| 0001 1000 | 24 | 18 | CAN | ␘ | ^X | 取消 |
| 0001 1001 | 25 | 19 | EM | ␙ | ^Y | 连线介质中断 |
| 0001 1010 | 26 | 1A | SUB | ␚ | ^Z | 替换 |
| 0001 1011 | 27 | 1B | ESC | ␛ | ^[ | 退出键 |
| 0001 1100 | 28 | 1C | FS | ␜ | ^\ | 文件分割符 |
| 0001 1101 | 29 | 1D | GS | ␝ | ^] | 组群分隔符 |
| 0001 1110 | 30 | 1E | RS | ␞ | ^^ | 记录分隔符 |
| 0001 1111 | 31 | 1F | US | ␟ | ^_ | 单元分隔符 |
| 0111 1111 | 127 | 7F | DEL | ␡ | ^? | 删除 |
ASCII 中 32-126 可显示字符表:
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|---|---|---|
| 0010 0000 | 32 | 20 | (space) |
| 0010 0001 | 33 | 21 | ! |
| 0010 0010 | 34 | 22 | ” |
| 0010 0011 | 35 | 23 | # |
| 0010 0100 | 36 | 24 | $ |
| 0010 0101 | 37 | 25 | % |
| 0010 0110 | 38 | 26 | & |
| 0010 0111 | 39 | 27 | ’ |
| 0010 1000 | 40 | 28 | ( |
| 0010 1001 | 41 | 29 | ) |
| 0010 1010 | 42 | 2A | * |
| 0010 1011 | 43 | 2B | + |
| 0010 1100 | 44 | 2C | , |
| 0010 1101 | 45 | 2D | - |
| 0010 1110 | 46 | 2E | . |
| 0010 1111 | 47 | 2F | / |
| 0011 0000 | 48 | 30 | 0 |
| 0011 0001 | 49 | 31 | 1 |
| 0011 0010 | 50 | 32 | 2 |
| 0011 0011 | 51 | 33 | 3 |
| 0011 0100 | 52 | 34 | 4 |
| 0011 0101 | 53 | 35 | 5 |
| 0011 0110 | 54 | 36 | 6 |
| 0011 0111 | 55 | 37 | 7 |
| 0011 1000 | 56 | 38 | 8 |
| 0011 1001 | 57 | 39 | 9 |
| 0011 1010 | 58 | 3A | : |
| 0011 1011 | 59 | 3B | ; |
| 0011 1100 | 60 | 3C | < |
| 0011 1101 | 61 | 3D | = |
| 0011 1110 | 62 | 3E | > |
| 0011 1111 | 63 | 3F | ? |
| 0100 0000 | 64 | 40 | @ |
| 0100 0001 | 65 | 41 | A |
| 0100 0010 | 66 | 42 | B |
| 0100 0011 | 67 | 43 | C |
| 0100 0100 | 68 | 44 | D |
| 0100 0101 | 69 | 45 | E |
| 0100 0110 | 70 | 46 | F |
| 0100 0111 | 71 | 47 | G |
| 0100 1000 | 72 | 48 | H |
| 0100 1001 | 73 | 49 | I |
| 0100 1010 | 74 | 4A | J |
| 0100 1011 | 75 | 4B | K |
| 0100 1100 | 76 | 4C | L |
| 0100 1101 | 77 | 4D | M |
| 0100 1110 | 78 | 4E | N |
| 0100 1111 | 79 | 4F | O |
| 0101 0000 | 80 | 50 | P |
| 0101 0001 | 81 | 51 | Q |
| 0101 0010 | 82 | 52 | R |
| 0101 0011 | 83 | 53 | S |
| 0101 0100 | 84 | 54 | T |
| 0101 0101 | 85 | 55 | U |
| 0101 0110 | 86 | 56 | V |
| 0101 0111 | 87 | 57 | W |
| 0101 1000 | 88 | 58 | X |
| 0101 1001 | 89 | 59 | Y |
| 0101 1010 | 90 | 5A | Z |
| 0101 1011 | 91 | 5B | [ |
| 0101 1100 | 92 | 5C | | |
| 0101 1101 | 93 | 5D | ] |
| 0101 1110 | 94 | 5E | ^ |
| 0101 1111 | 95 | 5F | _ |
| 0110 0000 | 96 | 60 | ` |
| 0110 0001 | 97 | 61 | a |
| 0110 0010 | 98 | 62 | b |
| 0110 0011 | 99 | 63 | c |
| 0110 0100 | 100 | 64 | d |
| 0110 0101 | 101 | 65 | e |
| 0110 0110 | 102 | 66 | f |
| 0110 0111 | 103 | 67 | g |
| 0110 1000 | 104 | 68 | h |
| 0110 1001 | 105 | 69 | i |
| 0110 1010 | 106 | 6A | j |
| 0110 1011 | 107 | 6B | k |
| 0110 1100 | 108 | 6C | l |
| 0110 1101 | 109 | 6D | m |
| 0110 1110 | 110 | 6E | n |
| 0110 1111 | 111 | 6F | o |
| 0111 0000 | 112 | 70 | p |
| 0111 0001 | 113 | 71 | q |
| 0111 0010 | 114 | 72 | r |
| 0111 0011 | 115 | 73 | s |
| 0111 0100 | 116 | 74 | t |
| 0111 0101 | 117 | 75 | u |
| 0111 0110 | 118 | 76 | v |
| 0111 0111 | 119 | 77 | w |
| 0111 1000 | 120 | 78 | x |
| 0111 1001 | 121 | 79 | y |
| 0111 1010 | 122 | 7A | z |
| 0111 1011 | 123 | 7B | { |
| 0111 1100 | 124 | 7C | | |
| 0111 1101 | 125 | 7D | } |
| 0111 1110 | 126 | 7E | ~ |
早期的一些传输协议,例如邮件传输协议 SMTP,只能传输可打印的 ASCII 字符。这样原本的 8bit 字节码(0-255)就会超出使用范围,从而到这无法传输。
这时,就产生了 Base64 编码,Base64 编码利用 6bit 字符来表达原本的 8bit 字符。
Base64 编码原理
上面我们知道了什么是 Base64 编码,知道了其包含的 64 个字符。它主要是通过 6bit 字符来表达原本的 8bit 字符。接下来我们一起学习下这一过程是如何进行的。
首先,6bit 显然不够容纳 8bit 的数据。6 和 8 的最小公倍数是 24,所以我们用 4 个 Base64 字符刚好能够表示三个传统的 8bit 字符。如下所示,字符串 Man 的编码图解如下:
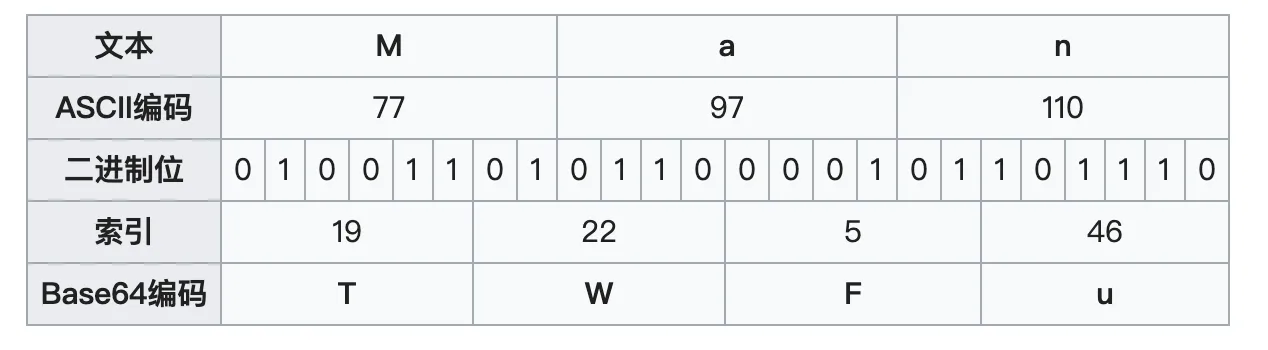
Man 的编码结果为 TWFu,显然,Base64 编码会多 1/3 的长度,这也解释了文中开头的疑问,为什么 Base64 编码后的体积会大 1/3。
Man 这个字符串的长度刚好是 3,我们能用 4 个 Base64 来表示。如果待编码的字符串长度不是三的倍数时应该怎么处理呢?
这是需要做一个特殊处理,假设带编码字符串长度为 10。这前 9 个字符可以用 12 个 Base64 字符表示。第 10 个字符的前 6bit 作为一个 Base64 字符,剩下的 2bit 后面需要先补 0,补到 6 位(此处补 4 个 0)作为第二个 Base64 字符,至于第三个和第四个 Base64 字符,虽然没有相对应的内容,我们仍需以 = 填充。
如下图所示,A 对应的 Base64 编码为 QQ==,BC 对应的 Base64 编码为 QkM=。

最后的问题就是解码啦,解码的过程比较简单。去掉末尾的等号 =。剩下的 Base64 字符,每 8bit 组成一个 8bit 字节,最后剩余不足 8 位的丢弃即可。
总结
本文篇幅较短,旨在简单介绍 Base64 编码原理。相信看完之后,大家一定能够理解为什么 Base64 编码后体积会增大 1/3,而不再是死记硬背这一特点。
备注: 完整的 ASCII 编码表
an unknown officer or employee of the United States Government [Public domain], 通过维基共享资源
本文作者 verymuch,吴文俊翻译,转载请注明来源链接:
原文链接: https://t.tie.pub/Je18f

